Architecture modulaire, microservices : on en est où ?
Les principes de l’architecture modulaire ne sont pas vraiment nouveaux. Par contre, l’implémentation de cette architecture dans les SI devient monnaie courante. En effet on voit aujourd’hui les fameux microservices fleurir un peu partout. Ce qui était un buzzword il y a quelques années est devenu la norme sur beaucoup de nouveaux développements. Ce billet dresse un constat sur les pratiques rencontrées dans les équipes, du côté métier et du côté technique.
Adoption des microservices
Cet article m’a été inspiré au départ par un sondage réalisé par O’Reilly en Juillet 2018 : The State of Microservices Maturity. Le sondage porte sur des entreprises ayant déjà implémenté des microservices dans leurs développements. Le rapport rend compte à la fois des aspects techniques liés aux microservices, du succès des projets, ainsi que des contraintes pour le métier. On y apprend notamment que pour les entreprises interrogées :
- Les architectures microservices sont largement adoptées sur les nouveaux projets, ainsi que les technologies nécessaires : conteneurs, intégration continue, tests automatisés…
- Les microservices sont considérés en majorité comme des succès
- Le découpage des microservices selon le périmètre métier n’est pas fait correctement.
Il est assez étonnant de constater qu’un élément primordial, la gestion des bounded contexts, n’est pas abouti alors même que l’adoption est massive et couronnée de succès !
DDD, Bounded context ?
La notion de bounded context (contexte délimité ?) vient du Domain-Driven Design (DDD).
Il s’agit de définir clairement les contours d’un domaine métier. Un domaine important sera séparé en différents sous-domaines. Ils peuvent parfois interagir les uns avec les autres, permettant l’aboutissement de processus métier impliquant plusieurs domaines.
Appliqué aux microservices, il s’agit “simplement” de spécifier un périmètre métier cohérent et unifié pour chaque service : pose de la problématique métier, objets et vocabulaire, comportements, interactions. Ce travail permet de mettre du sens sur les mots : un terme générique comme “client” peut avoir une signification très différente selon le contexte. Voici un exemple simpliste de 3 bounded contexts pour illustrer le propos :
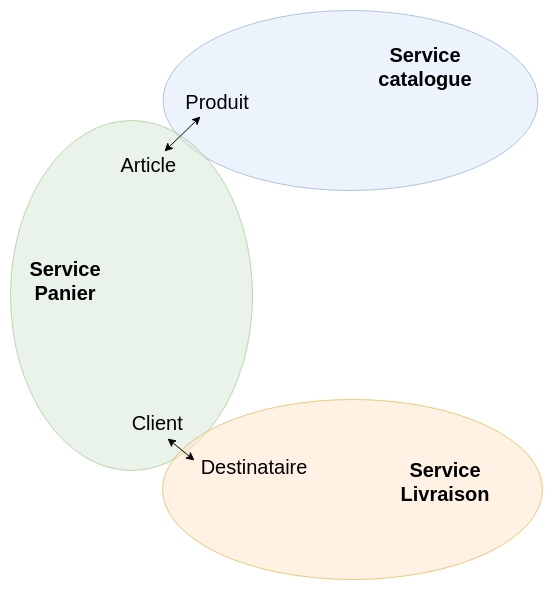
Ce travail est fondamental : la conception des microservices découle des bounded contexts. C’est ce qui garantit que les services conçus sont autonomes et indépendants. Si les contextes définis sont trop fins et trop couplés, il faudra livrer régulièrement plusieurs services en même temps, ce qui est très coûteux. On parle alors de nanoservices.
Le métier d’abord !
On l’aura compris, le point de départ d’une architecture microservices est un travail métier et non technique ! On doit avoir une isolation fonctionnelle claire pour chaque composant. Il semble que cet élément est souvent trop peu travaillé.
Il est nécessaire de faire des ateliers impliquant des personnes de différentes équipes, des experts métier et des développeurs. Il faut installer de nouvelles pratiques comme par exemple les ateliers d’event storming.
N’oublions pas que ce qui tourne en production est le code écrit par les développeurs. Le code doit donc correspondre au maximum avec le métier que l’on cherche à aider. En bref, les concepts du DDD (Domain-Driven Design) devraient être adoptés plus massivement.
Cohérence oui, Dépendance non
Un des gros risques en modélisant de nouveaux systèmes modulaires, est la tentation de grouper les services dans une roadmap globale et de faire dépendre fortement les services entre eux. Certes, il y a forcément des interactions entre les composants. Mais chaque équipe doit pouvoir avancer sans dépendre du travail des autres. Il faut préserver l’autonomie de chaque composant et des équipes associées. Pour cela on pourra :
- Concevoir chaque service comme pouvant fonctionner en mode seul au monde (le cas nominal peut être rendu sans dépendance externe)
- Utiliser des mocks (bouchons) pour les services externes non développés.
- Limiter les échanges de données en prenant en compte le contexte. Par exemple, un client dans le service panier n’a probablement pas besoin de tous les champs du référentiel.
- Eviter l’utilisation de librairies partagées.
La cohérence de l’ensemble est garantie par le respect des interfaces d’entrée/sortie de chaque service.
Alternative aux microservices : le monolithe modulaire
Une piste assez peu explorée est celle du monolithe modulaire. Mais c’est quoi exactement ? Pour produire un monolithe modulaire, il faut isoler les domaines métier comme on le ferait pour des microservices. Les deux différences notables sont que tout est dans la même base de code, et qu’on a une seule unité de déploiement. Mais la tâche est bien plus ardue qu’il n’y paraît. Pour implémenter un monolithe modulaire, il faut appliquer les principes suivants :
- Au préalable, délimiter les domaines métier “sur le papier” (bounded contexts)
- Délimiter les domaines métier dans le code : utiliser l’approche package by feature. Tout le code lié à un domaine est isolé.
- Définir pour chaque domaine des interfaces publiques pour interagir avec les autres : API (au sens interface, pas HTTP)
- Interdire les dépendances entre les domaines. On interagit uniquement avec les interfaces publiques ; on ne mélange pas les objets de différents domaines.
Au niveau des communications entre services, on n’a plus besoin de la couche réseau/protocole. Celle-ci est nécessaire dans une architecture microservices afin de transporter les données entre les services, sur le réseau. Dans le monolithe, les services communiquent directement entre eux, par exemple au sein de la même machine virtuelle Java. Cela simplifie grandement l’implémentation des interactions. En voici une illustration :
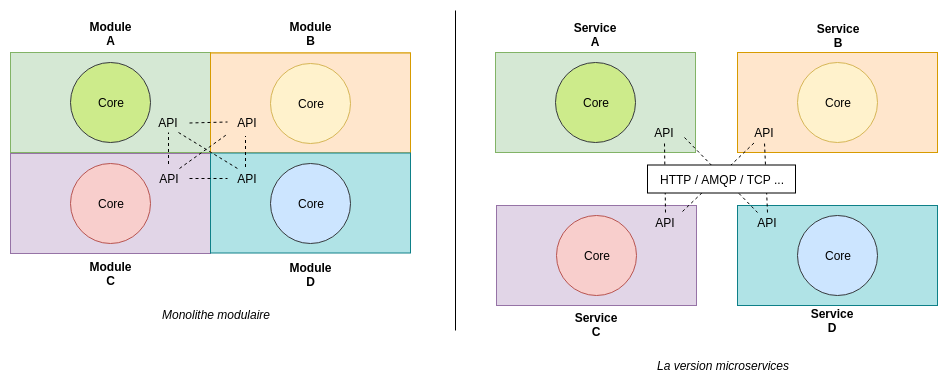
C’est une approche très intéressante mais qui demande une grande rigueur de la part de l’équipe de développement. Voici le retour d’expérience de Shopify sur le sujet.
Point de vue technique
Communication entre composants : HTTP m’a tuer
L’API REST HTTP est devenue la star des systèmes d’information. Les approches API first et open API sont aujourd’hui largement répandues. A tel point que de nombreuses personnes utilisent les termes “microservices” et “API” indifféremment pour parler de la même chose.
Or, le protocole HTTP ne devrait pas être le moyen de communication par défaut entre les composants d’une architecture modulaire. Les API HTTP sont un bon moyen d’exposer des données ou des commandes vers l’extérieur. Cependant, quand il s’agit de faire communiquer des services entre eux au sein d’un process, c’est une technologie relativement peu adaptée. Le protocole HTTP est synchrone et point-à-point ; il introduit un couplage fort entre les composants. Il nécessite des éléments techniques supplémentaires : API management, service discovery, gestion des authentifications… Enfin, quand on cumule des services trop couplés, et une communication omniprésente par HTTP : on arrive au syndrôme du plat de spaghetti !

Cela arrive quand un geste métier, comme un clic sur un site web, a pour conséquence de nombreux appels HTTP envoyés vers différents composants. Mécaniquement, la disponibilité de l’application diminue. Il faut intégrer des mécaniques de retry, circuit breaker…
Dans la mesure du possible, on privilégiera une approche événementielle pour implémenter les process : l’architecture orientée événements.
Gestion des contrats d’événements
Dans une architecture modulaire, si on a opté pour une approche événementielle, il faut prendre un soin particulier sur les échanges de données. Chaque message émis doit avoir un contrat clairement défini. Les contrats peuvent être spécifiés de différentes façons et sérialisés en différents formats. Par exemple, Apache AVRO permet une sérialisation binaire de taille très légère, et un versionning du contrat. Le JSON schema aura l’avantage de permettre la production d’échanges au format JSON, ce format étant omniprésent aujourd’hui.
Quelque soit l’outil choisi, on veillera à implémenter le principe de robustesse :
- Le consommateur d’un message lit uniquement les données qui l’intéressent, et ignore ce qu’il ne connaît pas
- tolerant reader : le consommateur doit accepter une donnée même si le format n’est pas celui attendu, tant qu’il est compréhensible
- l’émetteur d’un message respecte toujours le contrat : pas de suppression de champ par exemple.
Les développeurs et le dogmatisme
Quelques petites phrases entendues sur le terrain :
“C’est pas un microservice… il est trop gros !”
Le terme “microservice” est mal choisi, à mon sens. Il sous-entend que le service doit être petit (voire très petit). En réalité, la taille de la base de code n’a pas d’importance. La seule chose essentielle est que le service ait une responsabilité métier unique, clairement définie. Ensuite, selon la complexité du domaine, on peut avoir des services développés avec très peu de lignes de code et d’autres beaucoup plus volumineux.
“Ah non ! Ton batch ne peut pas interroger la base directement : elle appartient au microservice machin…”
Certes, une des premières choses qu’on apprend sur le sujet est qu’un microservice dispose de sa propre base de données, et lui seul peut y accéder. Cependant, à l’intérieur d’un domaine, on fera parfois émerger un composant technique supplémentaire pour pouvoir le scaler de façon indépendante. Par exemple, un service de notification, ou un batch de traitements de données. Si les composants sont fonctionnellement dans le même domaine, et maintenus par la même équipe, il n’y a pas de contre-indication justifiée au fait qu’ils partagent la même base de données.
“On fait une nouvelle brique ?”
C’est le développeur qui trouve ça génial et qui veut faire un nouveau composant, pour la moindre nouvelle fonctionnalité… :D
Conclusion
L’architecture modulaire permet à des équipes différentes de travailler en autonomie sur des composants distincts. Même si la mode est aux microservices, le monolithe modulaire est une alternative à étudier quand on n’a pas des besoins particuliers de mise à l’échelle.
La plus grosse difficulté est de faire correspondre les problématiques métier avec l’implémentation concrète dans les développements. On peut s’appuyer sur les principes du domain-driven design pour améliorer cela. L’event-storming permet par exemple de définir les domaines métier, ainsi que d’aligner les développeurs avec les experts du métier. Il facilite également l’adoption des architectures orientées événements, et du coup l’indépendance des briques applicatives.
Publié originellement sur le site de Salto Consulting le 20 Mars 2019.